SOP: Operaciones Avanzadas y Defensa de Datos
Este Procedimiento Operativo Estándar (SOP) define las directivas técnicas para el aislamiento de usuarios y la protección contra la eliminación accidental de datos.
1. Aprovisionamiento de Directorios de Usuario
En entornos empresariales, el aprovisionamiento debe ser estandarizado. Todo usuario requiere un directorio en /user/<username> con permisos restringidos.
- Ejecución de Script de Gestión:
# Automatiza creación de directorio y asignación de cuotas base
manage_hdfs_user.sh --add - Validación de Jerarquía:
hdfs dfs -ls /user
2. Implementación de Cuotas de Almacenamiento (Quotas)
HDFS permite dos niveles de restricción lógica para prevenir la denegación de servicio por agotamiento de recursos.
Las cuotas se gestionan en la sección HDFS > File Browser. Al seleccionar un directorio y pulsar en Edit Quota, se presentan dos límites críticos:
- Name Quotas (Archivos)
- Space Quotas (Bytes)
Limita el número total de nombres (archivos, directorios y enlaces) en un árbol de directorios.
- Uso: Prevenir el Small File Syndrome.
- Comando CLI:
hdfs dfsadmin -setQuota 1000 /user/bo_biz - UI Term:
File count limit - Error en Log:
NSQuotaExceededException - Definición: Límite de objetos (archivos/carpetas)
Limita el espacio físico total consumido, incluyendo todas las réplicas.
- Uso: Controlar el crecimiento del storage.
- Comando CLI:
hdfs dfsadmin -setSpaceQuota 50g /user/bo_biz - UI Term:
Disk space limit - Error en Log:
DSQuotaExceededException - Definición: Límite de bytes físicos (incluye réplicas)
Tras modificar una cuota, el mensaje informativo en la UI indicará: "The modified quota will appear in the usage reports after the new HDFS fsimage has been processed".
3. Defensa de Datos: Snapshots e Inmutabilidad
Los snapshots son copias de solo lectura del estado de un directorio en un punto del tiempo, capturando metadatos sin duplicar bloques de datos iniciales. Los Snapshots permiten capturar el estado del sistema de archivos. Para habilitarlos, el directorio debe estar marcado como Snapshottable.
Workflow en Cloudera Manager:
- Navegar a HDFS > File Browser.
- Seleccionar directorio > Botón desplegable > Enable Snapshots.
- Una vez habilitado, ejecutar Take Snapshot.
Se recomienda usar una nomenclatura estándar, ej: manual_backup_20240313. En la UI, aparecerán bajo la sección Snapshots Show All.
Protocolo de Recuperación Ante Eliminación Accidental
Si un archivo es eliminado incluso fuera del sistema de basura (-skipTrash), los snapshots permiten una recuperación instantánea.
# Paso 1: Localizar el archivo en el directorio oculto .snapshot
hdfs dfs -ls /user/bo_biz/.snapshot/first_snap/
# Paso 2: Restaurar mediante copia atómica
hdfs dfs -cp /user/bo_biz/.snapshot/first_snap/data.csv /user/bo_biz/
Configure políticas automáticas en Cloudera Manager (Replication > Snapshot Policies) para mantener una ventana de retención (ej: 3 snapshots horarios, 1 diario).
4. Inspección Forense de Bloques (fsck)
Ante una sospecha de corrupción de hardware, se debe realizar un análisis de consistencia a nivel de bloque.
# Reporte detallado de archivos, bloques y racks
hdfs fsck /user/allan_admin/latin/latin.txt -files -blocks -locations -racks
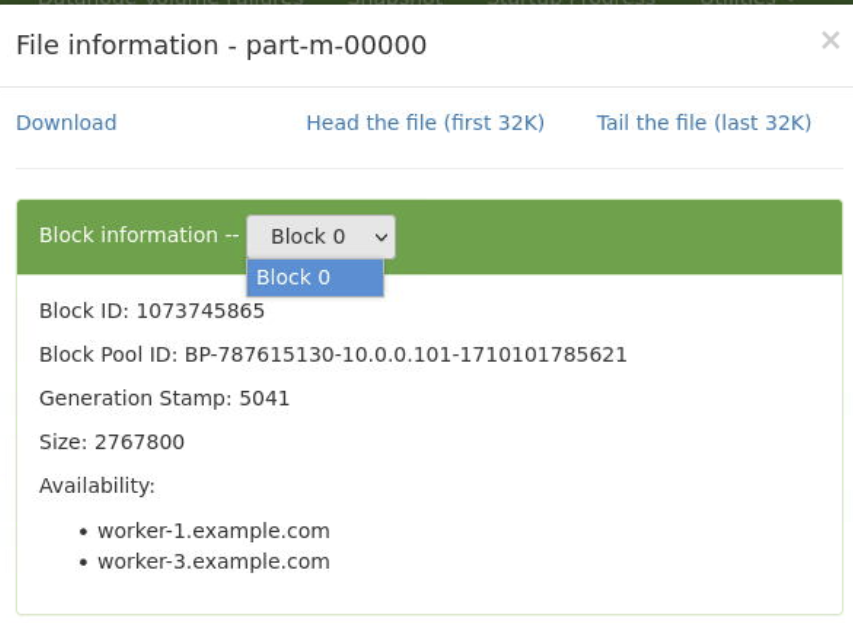 Análisis forense: Visualización de Block IDs y mapeo de DataNodes.
Análisis forense: Visualización de Block IDs y mapeo de DataNodes.
5. Gestión de Papelera (Trash Mechanism)
Cuando un usuario ejecuta hdfs dfs -rm, el archivo no se elimina permanentemente si el Trash Interval está activo.
- Parámetro en CM:
fs.trash.interval(Configuration > Search "trash"). - Comportamiento: El archivo se mueve a un directorio oculto llamado
.Trash/Current. - Recuperación: Mediante un comando
mv(Move) desde la CLI.
El flag -skipTrash elude este mecanismo. En la terminal aparecerá el mensaje: "Deleted /user/path", lo que implica la eliminación inmediata de los bloques de datos.
La papelera previene la pérdida de datos inmediata. El parámetro fs.trash.interval en Cloudera Manager determina el tiempo de vida de los datos eliminados.
- Ruta predeterminada:
/user/<username>/.Trash/Current/ - Recomendación Senior: Establezca un intervalo de 8 a 24 horas. Un valor superior puede agotar el espacio en clústeres de alta ingesta.
6. Diagnóstico de Alta Disponibilidad (HA)
Al acceder a la NameNode Web UI, es vital identificar el rol del nodo:
- Active: Procesa lecturas y escrituras.
- Standby: En espera. Si intenta navegar por este nodo, recibirá el error:
Operation category READ is not supported in state standby.
Relacionado: Optimización y Tuning de HDFS | Gobernanza de Configuraciones