SOP: Gestión y Defensa de Almacenamiento HDFS
Este Procedimiento Operativo Estándar (SOP) detalla las tareas de administración diaria para garantizar el aislamiento y la recuperabilidad en entornos CDP.
1. Aprovisionamiento de Directorios de Usuario
El aprovisionamiento debe realizarse mediante scripts de orquestación para asegurar los permisos adecuados.
- Ejecución del Script de Cuenta:
manage_hdfs_user.sh --add - Validación de Estructura:
hdfs dfs -ls /user
2. Implementación de Cuotas y Snapshots
La defensa del almacenamiento se gestiona preferentemente desde Cloudera Manager para mantener la trazabilidad.
- Cloudera Manager (UI)
- Administración vía CLI
- Cuotas: HDFS > File Browser > Seleccionar Directorio > Edit Quota.
- Establecer File Count Limit y Disk Space Limit.
- Snapshots: Seleccionar directorio > Enable Snapshots > Take Snapshot.
- Políticas: Replication > Snapshot Policies para automatizar la retención (ej. mantener las últimas 3).
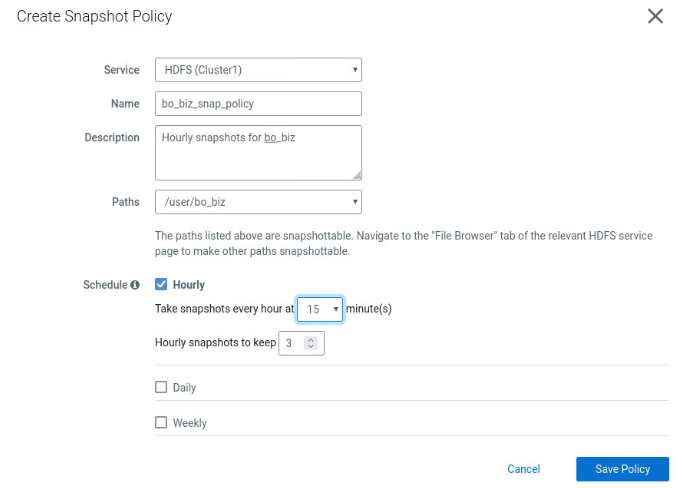
Procedimiento manual para situaciones de emergencia o automatización:
# Habilitar snapshots en un path
hdfs dfsadmin -allowSnapshot /user/bo_biz
# Crear snapshot manual
hdfs dfs -createSnapshot /user/bo_biz second_snap
# Reporte de estado del cluster
hdfs dfsadmin -report
3. Protocolo de Recuperación de Archivos
HDFS permite la recuperación forense mediante Snapshots o el sistema de Trash.
Si un usuario elimina accidentalmente un archivo usando -skipTrash, la recuperación se realiza mediante un cp desde el directorio oculto:
hdfs dfs -cp /user/bo_biz/.snapshot/first_snap/latin.txt /user/bo_biz/
Si un usuario elimina accidentalmente un archivo usando -skipTrash, la recuperación se realiza mediante un cp desde el directorio oculto:
hdfs dfs -cp /user/bo_biz/.snapshot/first_snap/latin.txt /user/bo_biz/
4. Mantenimiento Preventivo: El "Trash Interval"
Para evitar la pérdida accidental de datos, el administrador debe configurar el intervalo de persistencia en la papelera.
- Configuración: HDFS > Configuration > Buscar
trash. - Parámetros:
fs.trash.interval: Tiempo de vida de los archivos borrados (ej: 8 horas).fs.trash.checkpoint.interval: Frecuencia con la que el NameNode crea checkpoints de la papelera.
El uso del comando hdfs dfs -rm -skipTrash elude este mecanismo y elimina los bloques de datos de forma inmediata y no recuperable (salvo existencia de Snapshot previo).
5. Diagnóstico de Consistencia (fsck)
Ante sospechas de corrupción de bloques, se debe ejecutar la herramienta de chequeo de consistencia:
hdfs fsck /user/allan_admin/data/ -files -blocks -locations
Este comando reportará el Block ID, su ubicación física en los DataNodes y el estado de replicación actual.
Referencia: Laboratorios CDP 22-02, 22-03, 22-04